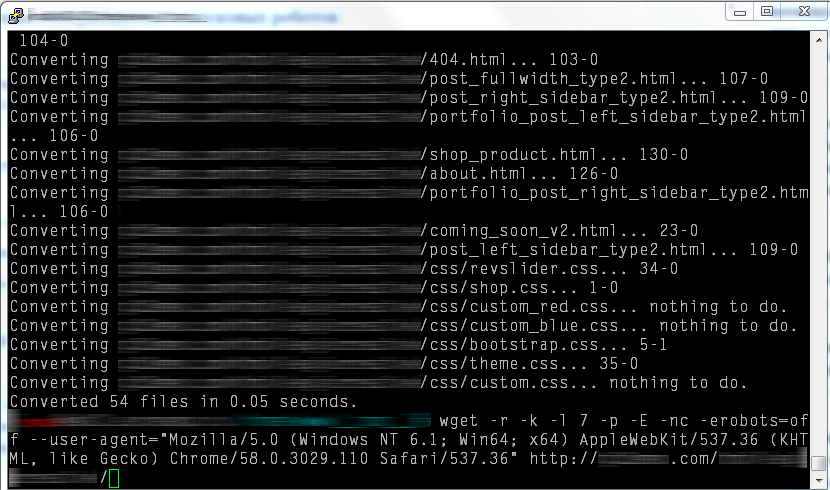
Так как Wget имитирует поисковой краулер (паук), то он по умолчанию просматривает файл robots.txt сайта и следует его инструкциям. Иногда вы хотите скачать сайт, но он не качается, т.к. в файле robots.txt указана следующая инструкция для поисковых роботов:
User-agent: * Disallow: /
Эта инструкция запрещает роботам индексировать всё на этом сайте.
Но нам надо скачать сайт! Используя аттрибут -erobots=off можно проигнорировать любые инструкции из файла robots.txt и успешно скачать сайт.
Пример команды целиком:
wget -r -k -l 7 -p -E -nc -erobots=off --user-agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36" http://www.example.com/