
Запускаем команду на своём VPS сервере:
wget -r -k -l 7 -p -E -nc --user-agent="Mozilla/5.0 (Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36" http://www.w3schools.com/
В итоге получаем директорию с именем www.w3schools.com и с содержимым:
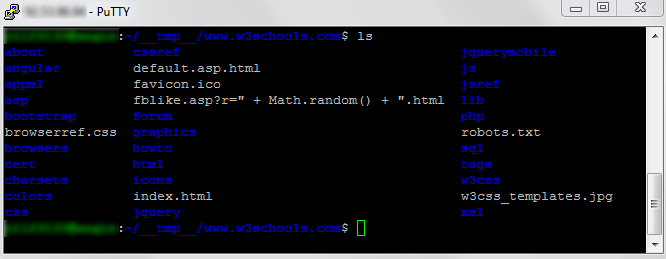
Скачать 1 страницу можно так:
wget -k -l1 -p -E -nc --user-agent="Mozilla/5.0 (Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36" http://www.w3schools.com/
Не у всех есть VPS сервер, и вообще некоторые люди Linux в глаза не видели ни разу. В этом случае поможет программа HTTrack Website Copier
Скачать эту программу можно здесь: http://www.httrack.com/
Но не во всех случаях получится скачать сайт целиком. Дело в том, что администраторы сайтов не хотят, чтобы их сайты выкачивали и потом парсили, рерайтили и еще что-либо вытворяли с их интеллектуальной собственностью, по этой причине они запрещают ботам скачивать сайт полностью.
Еще одна причина, — усложнение сайтов. Многие сайты написаны так, что контент отображается динамически. Запрашивается через клиенский код или генерируется на клиенте полностью. В этом случае общедоступные средства вроде указанных выше не помогут. Необходимо будет писать парсер отдельно.
Такие дела